I recently published Piccle, a static site generator for photographers. It's a commandline tool that uses the metadata within your photos to build a website. You can learn more & try it out or see it in action, but I want to talk about the philosophy behind it.
Genesis
Photographers have many options for online services to share their work, but none align with the conversations I have about photography. If I'm talking with somebody "about photography", that usually means a starting point like:
- "I just bought a new camera, I really like it..."
- "I went to Norway last year..."
- "I take a lot of portraits..."
And I want to follow these up with "Here, let me show you some photos."
This is harder than you might think! None of the major photo sharing sites1 make this easy, even though digital photos automatically contain a rich sea of metadata. "Date taken" and "camera model" is a given, and cameras increasingly add location info too. It's not much work for a human to add a description, title, and keywords when saving an edited image. But I don't think many people bother, because there's rarely a clear benefit.
It's a real shame that more sites don't use this metadata. Even if you only provide filtering or sorting by "Date taken", this satisfices for most of the use cases above2. Sadly, the popular sites either cannot toggle between "date taken" and "date uploaded", or hide the option away. Their focus seems to be "display one image", not "explore these works"; navigating your photos by metadata is not a priority.
So what's your best option? Most sites – not Instagram – will let you collect photos into albums. This is tedious and pointless. Why should you have to manually add photos to albums like "Taken in 2019" or "Trip to Norway"? It's trivial for the computer to do it – processing and filtering data is kind of their whole thing – but no: the work is on you. It angers me when computers needlessly burden humans. I have filled out countless forms like this:
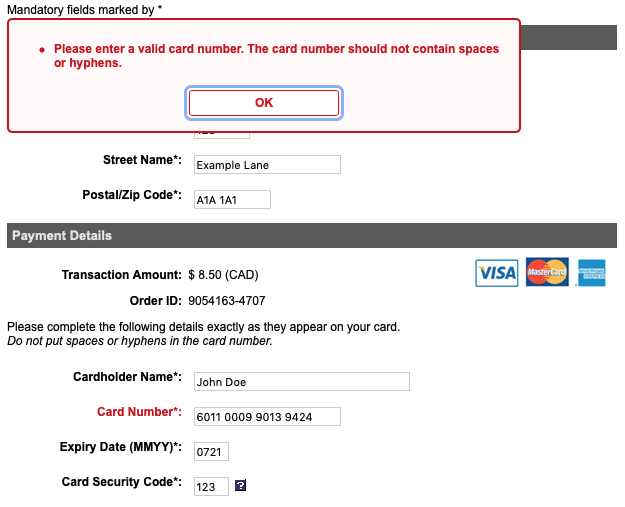
The computer knows what's up, but I still need to fix it? Just remove the non-numbers for me! Let me enter "6011000990139424" or "6011 0009 9013 9424", and you can strip the spaces. You already detected this specific case to display the error message. Detect this specific case, fix it, and let's move on with our lives.
Another drawback to building albums is that your labour is on the destination – where your photos are displayed – rather than the source (the photos themselves). Storing metadata in your files makes it available everywhere – any site you upload to, any app you open, and the operating system itself. Cataloguing your photos on a third-party site isn't portable – if you spend years building up a well-organised Flickr profile and want to move elsewhere, you'll have to start from scratch3.
What I wanted
I was unhappy with how existing web services presented my photography. They would show individual images nicely, but didn't let people explore my body of work. I didn't enjoy posting to them, and it never felt like I had a good place to link people when talking about photography. I also wanted to host the portfolio myself; you never know when an external service will wither away, be acquired, or shut down abruptly. And if your main "online home" is a third-party service, your audience is not your own4.
When a web developer starts thinking along these lines – a self-hosted, explorable photography portfolio – the big temptation is to build a "proper" web app. Something database-backed, with dynamic pages. It's doable, but there are multiple tar pits:
- There's a strong temptation to build an admin interface to manage and edit your photo's metadata. This is a classic example of something which sounds easy5, but isn't. The reason third-party sites do a bad job is because this is hard, not because they haven't thought of it.
- It suggests a lot of customisability, and now you are hurtling towards "content management system" rather than "show off my photos".
- It's hard for people to try it on their own photos. They must download your software, set up a database, set up a web server, add their photos, and run it. (You can make this a little easier with something like Docker – but now you're presuming they're familiar with Docker).
- It's hard for people to host it. If they want to publish their site – not just try it out – they need the technical skills to configure it on the external host.
- As well as needing a dynamic web server and a database, they must also deal with photo files. This means they either need to configure their server to allow uploads, or set up something like an S3 bucket too.
- How do people preview something before publishing? You have two tricky options: export photos from your local instance to a remote instance, or include the concept of "preview" vs. "published". Now we're back in "content management system" territory.
- How do you handle backups? An import/export system might help with that local instance → hosted instance problem, but it's yet another thing to code. And part of the problem is that you have both data and content; some database content, and some image files. So either you're crafting some kind of specialised binary blob or creating a ZIP file with a manifest – both of which seem somewhat fragile.
- Once they've got it working, it must stay working. Your code must persevere through language, system, and database upgrades. You need to think about cross-version compatibility and dealing with updates.
In short: your photographer is now a sysadmin.
"Stay working" is important. It's not enough for your software to work; it must keep working. If any of it breaks – the database, the web server, your web app – the user doesn't have a portfolio any more. And this content rarely changes – how often are you publishing photos? The keenest photographer posts a few times a day at most6. Why not generate a static site instead?
A database-backed website is software. A static site is a document. The former's alive – it only works when the software runs – and the latter is dead (it works as long as some other software is alive to read it). This neatly sidesteps a lot of the issues above: hosting static files is the most basic form of web hosting, both for a provider7 and an individual. There's no performance tuning or system administration. It's easy to try out and preview (view the generated site on your own computer) and easy to publish (copy the files to your webhost). And your portfolio is frozen in time – but still works as-is – if the generator breaks.
Mostly dead
Permit me a tautology: a static site is static. The code doesn't change unless someone regenerates it from new data. You might think this sounds dull, flat, and lifeless – but it doesn't have to be. Books are also static, as are movies and albums. Harry Potter, Die Hard, and Rumours are the same every time but feel vividly alive. Your static site can be the same.
Even though we're generating static files, we can include features that make it feel more alive. An Atom feed lets users subscribe for updates; including OpenGraph tags gives informative previews when people share links. CSS transitions & animations can give visual pizazz, and you can use a smattering of JavaScript for features like slide shows.
You could go further, and build a JavaScript-driven single page app. When people think of SPAs, they think of JavaScript talking to an HTTP API. But the API is optional: our JavaScript can read a static JSON file instead. After the initial page load we can render everything in the browser, returning only to the server for images. This gives you the best of both worlds: the speed and reliability of a server-rendered site, combined with the slickness of client-side rendering. All the contemporary JavaScript options are available to you, if you want them.
I still don't know if I want them, though I've designed Piccle with the presumption I do. The idea of switching to client-side rendering after the initial page load is attractive; it's the progressive enhancement dream scenario. The question is: is it worth loading a megabyte of JSON for that8? Piccle already feels snappy when changing pages, and the HTML is very light. I'll experiment, but it might not be an improvement.
What I built

Piccle is a command-line utility built in Ruby. Given a directory of images, it generates a complete site. There's still a database under the hood, but acting as a cache instead of powering the website directly.
One command generates your site, but it's a multi-step process internally:
- New and updated metadata is extracted from the photos to the database.
- The photos are faceted based on an aspect of the metadata (eg. "camera model", "date", "location"). Each facet is implemented as its own "stream", which groups photos according to its facet. Streams are registered upfront; then, as each photo is added, the stream adds its own data.
- The website is generated. This uses a NodeJS helper utility for performance reasons. (There's a pure Ruby renderer available too, but it's impractically slow for more than a handful of photos.)
Earlier versions supported serving a website from the database, but some queries (and working both statically & dynamically) were too unwieldy. It was simplest to abandon that approach.
I describe Piccle as a zero-configuration tool, but that's a lie. There are some customisations available. "Events" are the most notable – named date ranges, handy for themed shoots or trips. I don't know a good way to store these in EXIF data, so events are defined in YAML instead. Generating a gallery from one command makes it easier to slot Piccle into your existing workflow – you can set an Automator action to watch a directory for new files and then run Piccle. Add an rsync command too: now your photo is automatically published to the web the instant you export your photo from your image editor.
Overall, there's nothing technically revolutionary in Piccle. The value is in how lots of small elements come together to be pleasant to use. Good help text and sensible defaults in the interface; responsive output so galleries look great on phones, tablets, and desktops. Quilt images for each subsection, so shared links look good.
But at a higher level, I want to hide all of this from users. Piccle should feel obvious; of course social media shares look good. Of course you run one command and get a complete site that's easy to deploy. Of course you can browse by date, location, and tags. Photographers shouldn't need to know anything about web development, or databases, or programming. They should feel like Piccle is a small tool doing one thing well – even if, underneath, it's working hard to do ten things well.
Built for everybody, and yet not
A static site is a good technical fit for a photo gallery. It's also simpler for users: "run once and put the output on the web" is easier than "keep this database-backed system running." Simplicity is one of my goals for Piccle; I want to bring better tools to more people, to make it easier for people to host their own photo galleries. From one perspective, I achieved this: Piccle takes a directory of images and generates a nice-looking website with one command. Publishing HTML is easier than hosting a CMS or a Docker container. If you have some photos in a folder you can try it easily. The generated gallery is OK even if your photos have limited metadata.
But I mentioned Piccle to a friend a couple of months ago, and she said “Let me know when it’s ready & I’ll get the people in my camera club to test it.” This should have been delightful, but I was deeply reluctant.
A camera club is a group of people who own complicated equipment, are enthusiastically operating them, and are technical enough to transfer photos onto a computer & edit them using specialist software. Yet there's a huge distance between them and someone who finds Piccle easy to use. How many camera club members already use a command line? How many will have Ruby and NodeJS installed? For me, Piccle is straightforward9. But if you’re not like me, it’s arcane.
I built Piccle for my own use, but I'm bothered by this gulf between my goal – break down publishing obstacles – and the result. Imagine you're a member of that camera club: you’re into photography, you have your photos on your computer, and you want to make a website for them. Your side quests include:
- Learn enough about the CLI to navigate directories and run commands.
- Install Ruby and NodeJS (or check your OS includes them).
- Install Piccle. Hopefully all of its dependencies install cleanly – otherwise you’ll need to chase down things like ImageMagick and SQLite libraries.
- Find a suitable web host, set up an account, and figure out how to upload all your files in one go.
- Figure out how to integrate all of this into your workflow. To be useful this can’t be a one-time process; it’s got to be repeated, and reliable, and feel natural.
I don’t have a solution for this. Packaging Piccle up into a GUI and shipping static versions of Ruby/Node/etc is one possibility10. It’s not how I want to use Piccle, but it would open it up to a wider audience. This is an open question, and one I’m still mulling over.
Next steps
Now that I’ve launched Piccle I’ve swung back towards photography rather than coding: editing past images and adding metadata to existing shots. It's satisfying seeing it become closer to a comprehensive archive of my photography, and it’s taught me more about my own work than I expected. This is an ideal outcome: it's nice when programming sparks an interest in programming, but better when it sparks an interest in creativity. Nothing's better than when a computer inspires you to create.
-
Flickr is the exception here; they have superb filtering tools. But it's not a perfect solution: you have to pay if you want more than 200 photos visible, the filters aren't easy to find, and you can't host it yourself. ↩
-
"I just bought a new camera" implies "show me the most recent photos". You can probably recall the rough month/year of a trip, so jumping to a given date works for travel. ↩
-
Or hope that your new home has written a special importer, just for Flickr. ↩
-
There's a philosophy called POSSE – "Publish Own Site, Syndicate Elsewhere." It boils down to "Keep your creative stuff on your own domain, and federate it out." Your blog should live on your own website. Publish your articles on Medium, Substack, Wordpress, etc. if you like – but keep the canonical version on your own website. Ideally, you get the best of both worlds: the increased audience from the third-party sites, and the control inherent in first-party hosting. It's not as popular as it was, but it still has a lot of appeal for me. ↩
-
To a programmer. ↩
-
Editing takes time, and if people do produce a lot of work in one go they're likely to publish it as one batch. ↩
-
Any webhost can host static files – as can Amazon S3, Github Pages, or Geocities. ↩
-
You can split the JSON and load chunks on-demand, but why? You could load the actual page instead. ↩
-
I am a programmer, spend a lot of time on the command line, and generally wish for a simpler time on the internet. ↩
-
This sounds tricky to implement across Windows, Mac, and Linux. ↩